기초공감과학 에세이 “로보트가 아니에요” 테스트에 숨겨진 비밀
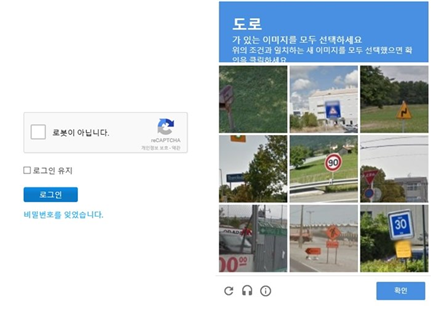
사진 출처: wikitree
인터넷 서핑을 하다 보면 위와 같은 화면을 많이 접한 것 같아요. 매번 ‘왜 도로나 표지판의 사진을 일일이 골라야 하지?’ 라는 의문이 들기도 합니다. 이런 로봇이 아닙니다 테스트는 왜 할까요? 이 시험은 대체 어디에 이용되는거죠?CAPT CHA의 등장에서 언급했듯이 어떤 사용자가 실제 인간인지 컴퓨터 프로그램인지를 구별하기 위해 사용되는 방법을 “CAPTCHA(Completely Automated Public Turing test to tell Computers and Humans Apart)”라고 합니다. 여기서튜링테스트라는용어가나오는데,이것은20세기수학자인암호해독자인앨런튜링이제시한인공지능판별법입니다. 앨런 튜링은 컴퓨터가 의식을 가진 사람처럼 자연스럽게 대화를 나눌 수 있다면 그 컴퓨터에도 의식이 있다고 봐야 한다고 주장했습니다.

▲튜링 테스트 사진 출처: Prezi
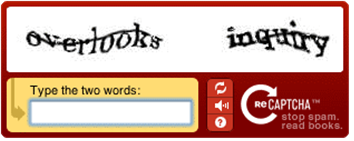
CAPT CHA는 인간이 아닌 봇(bot)이 무차별적으로 웹사이트를 공격하거나 계정을 해킹하는 등 악의적으로 사용되는 것을 방지하기 위해 만들어졌습니다. 광고성 게시물이나 아이디 자동 작성 방지, 온라인 선거를 할 때도 이용됩니다.다양한 방식을 사용하는 CAPT CHA 용도가 다양한 만큼 테스트 방법에도 여러 종류가 있습니다. 가장 보편적인 형태는 ‘텍스트 CAPT CHA’ 로 기존 텍스트와 이미지를 왜곡된 형태로 변형한 후 이미지로 표시된 문자가 요구하는 내용을 입력하는 방법 입니다. 변형된 이미지는 사람이라면 쉽게 인식할 수 있지만 컴퓨터 프로그램은 인식할 수 없기 때문에 테스트를 통과해야만 테스트 대상자가 아님을 판정할 수 있습니다.
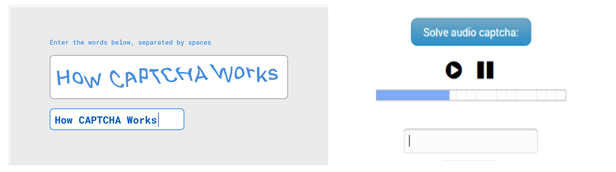
하지만 텍스트 CAPTCHA는 시각 장애나 난독증이 있는 사람은 사용할 수 없다는 단점이 있었습니다. 그걸 보완하기 위해서 등장한 게 ‘오디오 CAPT CHA’입니다. 컴퓨터와 인간의 구어 인식 능력의 차이를 이용한 것으로 잡음에 섞여 들리는 단어를 입력하도록 설계되어 있습니다.

▲텍스트 CAPTCHA와 오디오 CAPTCHA 사진출처: CloudSEKCAPTCHA가 고문서 해독에 사용된다?미국 카네기멜론대 연구원들은 전 세계 사람들이 CAPT CHA를 푸는 데 쓸 시간을 효율적으로 활용할 수 있는 방법이 없을까 고심했습니다. 그때 떠오른 것이 고문서 해독이었어요. 당시 도서관에서는 고문서를 디지털화하는 작업이 한창 진행되고 있었지만, 잉크가 번지거나 낡아 컴퓨터를 읽어내는 것은 곤란했습니다. 연구원들은 이 고문서에 등장하는 단어를 CAPT CHA에 이용했습니다. 고문서의 단어와 기존 CAPT CHA에 적혀있는 단어를 하나씩 붙여 표시하고, 그 중 CAPT CHA를 통과한 답변만 수집하여 사람을 판별한 후 이 답변의 고문서 해독 데이터를 수집하는 것입니다. 이 방식을 ‘reCAPTCHA’라고 부릅니다.
▲reCAPTCHA v1 사진출처: I T world
하루에 입력하는 약 1억 개의 단어로 한 해 250만 권의 책을 해독한 덕분에 막대한 양의 데이터를 모을 수 있었고, 2009년 구글은 이를 인수해 ‘구글 북스 라이브러리 프로젝트’에 이용했습니다. 그 뿐만 아니라 표지판이나 간판에 쓰여진 읽기 어려운 문자도 reCAPTCHA로 해독해, 보다 정확한 Google 지도 서비스를 제공하는데도 활용하고 있습니다.※ 구글북스 라이브러리 프로젝트=구글이 2004년 시작한 프로젝트로 대학도서관의 책을 전자문서로 만들어 검색, 열람할 수 있도록 한 것.저작권 유효기간이 만료된 책은 전문을, 저작권이 남아 있는 도서는 목차, 내용 일부를 공개하고 검색어를 통해 책과 본문의 내용을 찾아보는 서비스도 제공한다. 구글이 프로젝트를 통해 데이터베이스화한 도서는 2000만 권이 넘는다.reCAPTCHA, 자율주행 자동차에도 이용되고 있다!
▲ no CAPTCHA reCAPTCHA ( reCAPTCHA v2 )
하지만 왜곡된 문자를 읽는 기술이 발전하면서 텍스트 reCAP TCHA 방식에 한계가 생기자 2014년 구글은 이미지를 이용한 ‘noCAP TCHA reCAP TCHA’를 고안했습니다. 위의 사진과 같이 어떤 이미지를 표시하고 지시할 대상이 포함된 타일을 모두 선택하도록 하는 방식입니다. 사진에서 개체를 정확히 파악하는 것은 왜곡된 문자를 읽는 것만큼 프로그램이 수행하기 어려운 작업이며 사진은 왜곡된 문자열보다 쉽게 얻을 수 있기 때문에 종종 사용되고 있습니다.
이렇게수집된데이터는자율주행자동차인공지능학습에이용된다는사실을알고계셨나요? 인공지능 연구 초기에는 가장 기초적인 고양이와 개의 사진을 비교 선택하는 문제가 많이 제공되었으며, 최근에는 구글이 자율주행자동차 연구에 박차를 가하면서 도로표지판, 신호등, 차량 등의 유무를 묻는 문제가 주로 제공되고 있습니다.
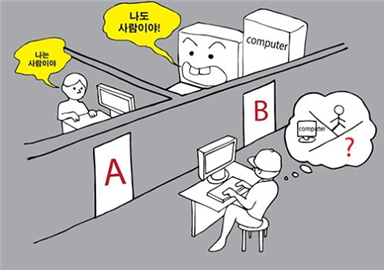
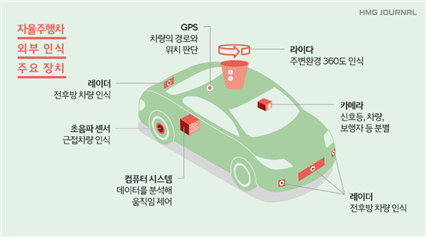
사진 출처 : HMG JOURNAL
자율주행차는 먼저 사람의 전방물건이나 차선, 신호등, 보행자등 도로의 복합환경을 인식하고 이를 분류하는 과정에서 교통표지판을 인식합니다. 그러나 역광이나 안개, 상향 등과 같은 외부 조건에 약하고 센서 오류가 발생할 수 있다는 단점이 있습니다. 이를 보완하기 위해 카메라 또는 렌즈를 2개 사용하여 사람의 눈처럼 교통표지판을 3차원으로 인지할 수 있도록 개발되었습니다.
하지만 카메라처럼 바로 보고 인지하는 것이 아니라, 미리 예측을 할 수 있으면 어떨까요? 인공지능은 이미 설치된 사물이나 도로 환경에서 수집한 빅데이터를 분류함으로써 이러한 예측을 가능하게 합니다. 이 인공지능을 reCAPTCHA를 통해서 학습시키는 겁니다. 딥러닝 기반의 카메라 영상인식 기술은 내비게이션 데이터로 도로의 경사도, 굽음, 도로표지판 등의 정보를 실시간으로 전송할 수 있습니다.앞으로 어떤 새로운 방식이 등장할까.
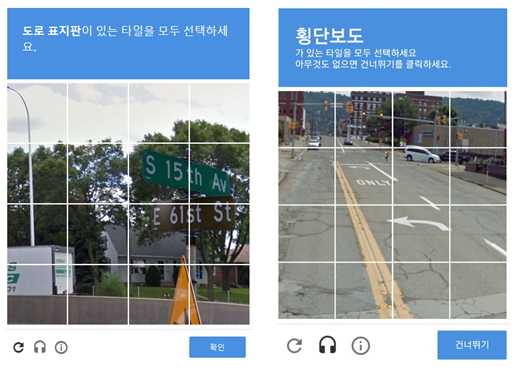
사진 출처 : 구글
noCAPTCHA reCAPTCHA 종류에는 앞서 말한 이미지를 선택하는 테스트 외에 단순히 사각상자를 클릭하는 테스트가 있습니다. 구글은 사용자의 IP 주소와 쿠키 정보를 이용하여 박스 주변에서 마우스 포인터의 미세한 움직임을 포착하여 높은 정밀도로 사람과 봇을 구분합니다.
구글에서 가장 최근에 개발한 reCAP TCHA 방식은 사용자가 클릭할 필요조차 없어진 invisible reCAP TCHA 방식입니다. 사용자가 특정 행동을 하지 않더라도 컴퓨터가 자체적으로 보통 사용자의 행동 패턴을 분석하여 봇이 아니라고 판단할 수 있습니다. 하지만 편리함을 얻는 만큼 온라인에서의 행동이 대부분 수집, 분석된다는 의미이기도 하므로 사생활 및 개인정보 보호 측면에서는 경각심을 가져야 할 부분이기도 합니다.
나날이 고도화되어 가는 인공지능을 인간과 구별하기 위해 앞으로 어떤 새로운 방식의 리캡챠가 등장하게 될까요?
< 資料 出典 > 1 . Largescale CAPTCHA survey ( 2018 ) https://udspace.udel.edu/bitstream/handle/19716/23980/Greene_udel_0060M_13475.pdf ?sequence=2&is Allowed=y2. 자율주행차가 세상을 인식하는 방법(2019) https://1boon.kakao.com/HMG/5cae99deed94d20001241a6c